
Faces in Places
Academic Project
Design For The Future
SPRING 2022
TOOLS
ML4A Colab: Semantic Segmentation, SPADE
SKILLS DEVELOPED
UX Design
Timeline
1 Weeks
Design For The Future
SPRING 2022
TOOLS
ML4A Colab: Semantic Segmentation, SPADE
SKILLS DEVELOPED
UX Design
Timeline
1 Weeks
Apply machine learning for image-making.
Using Semantic Segmentation and SPADE, I created a series of images that explore how machine learning detects and deconstructs face illusions.
Can machine learning detect faces on objects?
How does machine learning treatment of objects with faces change our perception of them?
Faces are equally as detectable in the images generated with machine learning.
Scientists at the University of Sydney have found that not only do we see faces in everyday objects, our brains even process objects for emotional expression, much like we do for real faces. This phenomenon is called face pareidolia, seeing faces in random objects or patterns of light and shadow.
I chose five images of various objects, each a facial illusion. They are all made with different materials and are different shapes.





I ran the Semantic Segmentation model over five images of objects with faces to see how it would label the different segments of the image.

The Semantic Segmentation model adds a label map on top of the image. I used two labeled images and the original image to experiment with SPADE using the pre-trained model coco.
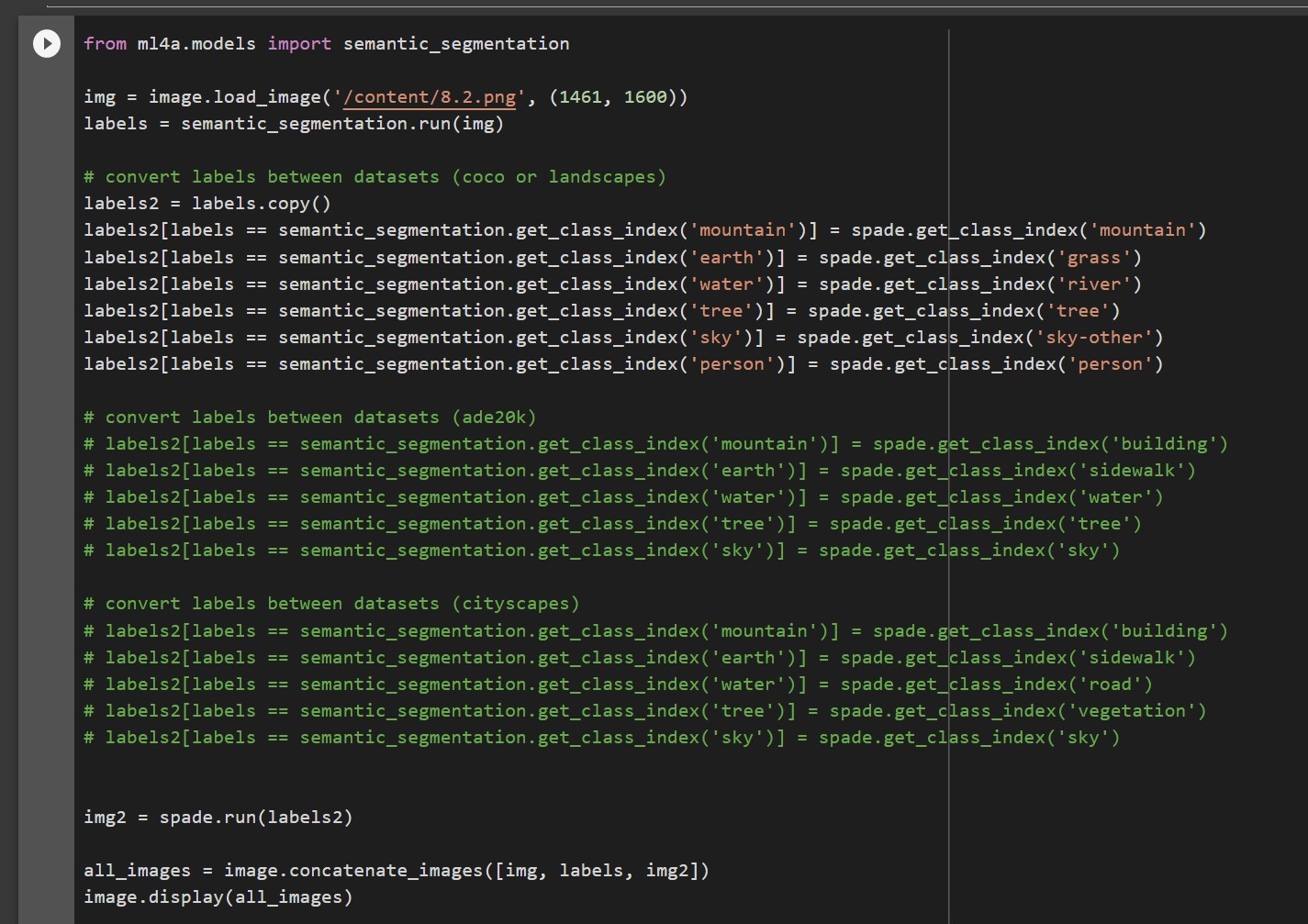
I was surprised to see how varied the image outputs were and how different they were from the original image.















I asked four people to tell me what they saw in each image.
If they saw a face (person, animal, robot, etc.), I noted it with a smiley face icon under the image.
















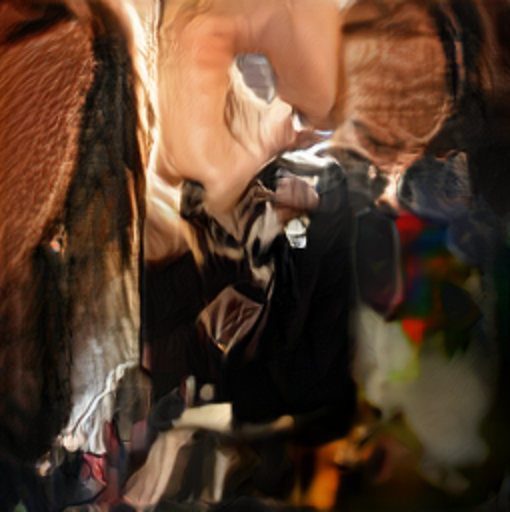



The image output wasn't what I had envisioned, but that's the nature of machine learning. However, I liked the shapes it created and how varied each image is. In addition, the images brought out a lot of interesting, creative responses from the people I surveyed. It was fascinating hearing about different people's perceptions, similarities, and differences in image interpretation.
At one point, I kept getting errors, and it wasn't clear until I reloaded and tried again that I did not have enough GPUs. Unfortunately, Google collab doesn't indicate how many GPUs you have and cap it based on your use, disrupting a project. So I bought more to continue working.
In hindsight, SPADE might have interpreted the images as faces if I had manually changed the segmentation colors in photoshop. Next time, I'll experiment with that to try and recreate a human face.